In his blog post on artificial intelligence (AI), GovTech Graduate Jonathan Manning draws on the New Zealand Law Foundation: Government use of artificial intelligence in New Zealand (the NZFL report) to discuss the role and effectiveness of explanation tools.
As algorithms and AI become ubiquitous we all become ‘data subjects’ to organisations such as governments and businesses.
In response, regulations such as the EU’s General Data Protection Regulation are beginning to emerge. The New Zealand government is currently exploring how governments, business and society can work together to meet the challenge of regulating AI.
A part of this challenge is ensuring when things like algorithmic harm arise, we can explain what happened and why so that mistakes can be fixed and not repeated or obscured. This post focuses on a particular explainability problem that some kinds of AI present.
How do we explain ourselves?
What would you say if someone asked you to explain why you ate an apple and not a banana at lunch?
We may use things like our agency — “I just like apples more”, our intuition — “today feels like an apple kind of day”, our rationality — “I ate a banana yesterday and it is better to not always eat the same fruit”.
Or it may be some combination of these and other factors.
We may also be accurately recounting our thinking or retrofitting an explanation to suit our decision.
When we are asked why we ate the apple we are not being asked to explain our own cognitive processes — no one expects a report on the psychological activity and mechanisms that underlie our decisions.
We don’t know or understand enough about these processes, and if we did, what use would they be to the person who is asking?
Would the decision “eat the apple” be apparent to anyone, even an expert, from a heatmap of brain activity or from a complex diagram of neural connections?
Complexity
Perhaps something similar is happening when we ask for an explanation of decisions made by AI. The explainability problem this blog post is addressing occurs in AI that implement machine learning algorithms upon deep neural networks — or ‘deep learning’ for short.
These systems “...mimic the brain’s own style of computation and learning: they take the form of large arrays of simple neuron-like units, densely interconnected by a very large number of plastic synapse-like links.”
The sheer size and complexity of these networks is part of why their decisions are so difficult to explain, in the same way a massive and interconnected decision tree is difficult to follow. However, explaining complexity alone is not the whole story when it comes to deep learning.
Humans have a reasonable chance of being able to understand a decision tree...but they have no chance of understanding how a deep network computes its output from its inputs.
Independent decision-making
A key difference is that in a decision tree the importance of each branch is known and doesn’t change. In a deep learning neural network the importance or ‘weight’ of each neuron is intentionally not known and does change.

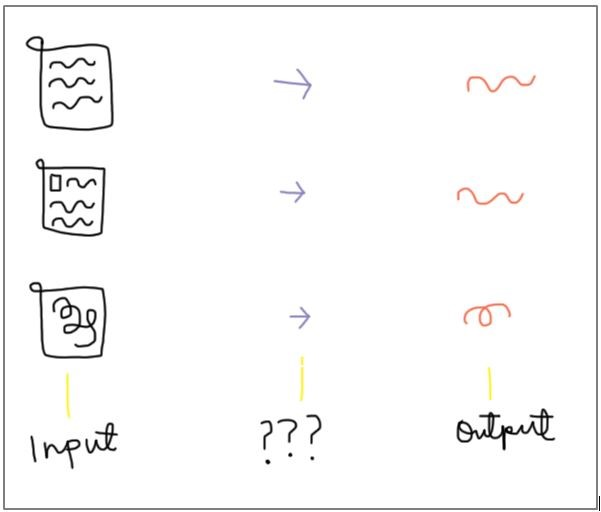
Detailed description of illustration
The illustration is of a simplified machine learning system. It has 3 columns and 3 rows with an image in each cell.
The first column shows 3 documents (inputs), the second column shows 3 question marks (inputs being processed), and the third column shows 3 lines (outputs).
This illustration demonstrates known information being inputted into the system, being processed in an unknown way, and being outputted as simplified and different information.
This is because a machine learning system is given known inputs and has expected outputs, but how the system decides to process the information in-between is unknown.
The system trains itself by adjusting the weights of each neuron in pursuit of an accurate outcome. The system “essentially derives its own method of decision-making” (NZLF report) to earn its title of artificial intelligence.
It is this independent decision-making within a complex environment like a neural network that causes the explainability problem this post is focused on.
...it is simply not known in advance what computations will be used to handle unforeseen information. Importantly, neither the operator nor the developer will be any the wiser in this respect.
Explanation tools
If we want to build a predictive system that can convey to a human user why a certain decision was reached, we have to add functionality that goes beyond what was needed to generate the decision in the first place.
The development of explanation tools that add this functionality is a rapidly growing new area of AI.
By adding functionality into the deep learning system we do not need to compromise it’s independent decision-making and complexity for the sake of explainability. By having two models we can potentially get the best of both worlds.
While the original model can be very complex, and optimised to achieve the best predictive performance, the second model can be much simpler, and optimised to offer maximally useful explanations.
As well as being technically advantageous this ‘model of a model’ approach “may avoid the need to disclose protected IP or trade secrets” (Slave to the Algorithm?) of the original model.
This means explanation tools may offer a way to partially open technological and legal black boxes at the same time.
What kind of explanation should we ask for?
Just as asking a person to report on their psychological processes is unlikely to be a good explanation for why they ate the apple, so too is asking a deep learning system to report on the actual weights and logic it used to make a decision.
Perhaps it is also true that just like the second order explanations we expect of a person are more meaningful, so too are the second order explanations of deep learning systems.
Whether second order explanations will be satisfactory is an open question. What is known is that:
To satisfy the requirements of current New Zealand law, then, it appears that it will not suffice to provide information about the decision in a manner that is incomprehensible to all but experts. Instead, means must be found to render these explanations sufficiently clear for the individual themselves, the public, and any authority with the power to review that decision.
What explanation tools won’t do
Explanation tools offer a way to let a little light into the black box of deep learning systems. They are a new and promising area of AI research that may help future regulation. However, they should be treated as a tool within a wider toolkit.
It should not be assumed that all deep learning systems equipped with explanation tools are able to be deemed transparent and safe - there is no guarantee that explanation tools will reveal bias and discrimination.
...algorithmic models, inputs and weightings, however disclosed, may still not show that a system has been designed to be biased, unfair, or deceptive.
Even if there were such a guarantee it should not be assumed that that individuals would be able to make any use of it — there are too many relevant problems with relying on individuals to challenge algorithmic decisions to discuss in this post, see Slave to the Algorithm? for more.
Even for an expert it should not be assumed that adding an explanation tool plus getting access to the entire dataset can guarantee a deep learning system is transparent and safe.
...researchers are discovering now how difficult many of these problematic but non-obvious issues can be to spot even when they have the whole dataset to hand.
Conclusion
There is much more to do to meet the challenge of regulating AI. Providing reassurance to the public that they are treated ethically as data subjects relies on broad themes like transparency and trust. Being able to more meaningfully explain the weights and logic behind particular decisions of deep learning systems is one small part of the answer that shows a lot of promise.
We want to hear from you
We want to continue the conversation to incorporate the various experiences and perspectives on ethics and AI within New Zealand. This will influence the future development of AI — and how regulation can be used to build and maintain public confidence in digital technologies.
If you want to keep up to date on the progress of this project and be involved in the next stages, email DRE@dia.govt.nz.
References
Government use of artificial intelligence in New Zealand
This blog post draws from Sections 4B and 1B of the New Zealand Law Foundation’s “Government use of artificial intelligence in New Zealand” report by Colin Gavaghan, Alistair Knott, James MacLaurin, John Zerilli and Joy Liddicoat, 2019.
Slave to the Algorithm? Why a ‘right to an explanation’ is probably not the remedy you are looking for.
Lilian Edwards and Michael Veale, 2017.
Enslaving the Algorithm: from a ‘right to an explanation’ to a ‘right to better decisions’?
Lilian Edwards and Michael Veale, 2018.

{kind=link}